A Landmark-Aware Visual Navigation Dataset
Click here to read the paper.
Abstract
Map representation learned by expert demonstrations has shown promising research value. However, recent advancements in the visual navigation field face challenges due to the lack of human datasets in the real world for efficient supervised representation learning of the environments. We present a Landmark-Aware Visual Navigation (LAVN) dataset to allow for supervised learning of human-centric exploration policies and map building. We collect RGB observation and human point-click pairs as a human annotator explores virtual and real-world environments with the goal of full coverage exploration of the space. The human annotators also provide distinct landmark examples along each trajectory, which we intuit will simplify the task of map or graph building and localization. These human point-clicks serve as direct supervision for waypoint prediction when learning to explore in environments. Our dataset covers a wide spectrum of scenes, including rooms in indoor environments, as well as walkways outdoors. Dataset is available at DOI: 10.5281/zenodo.10608067.
Overview
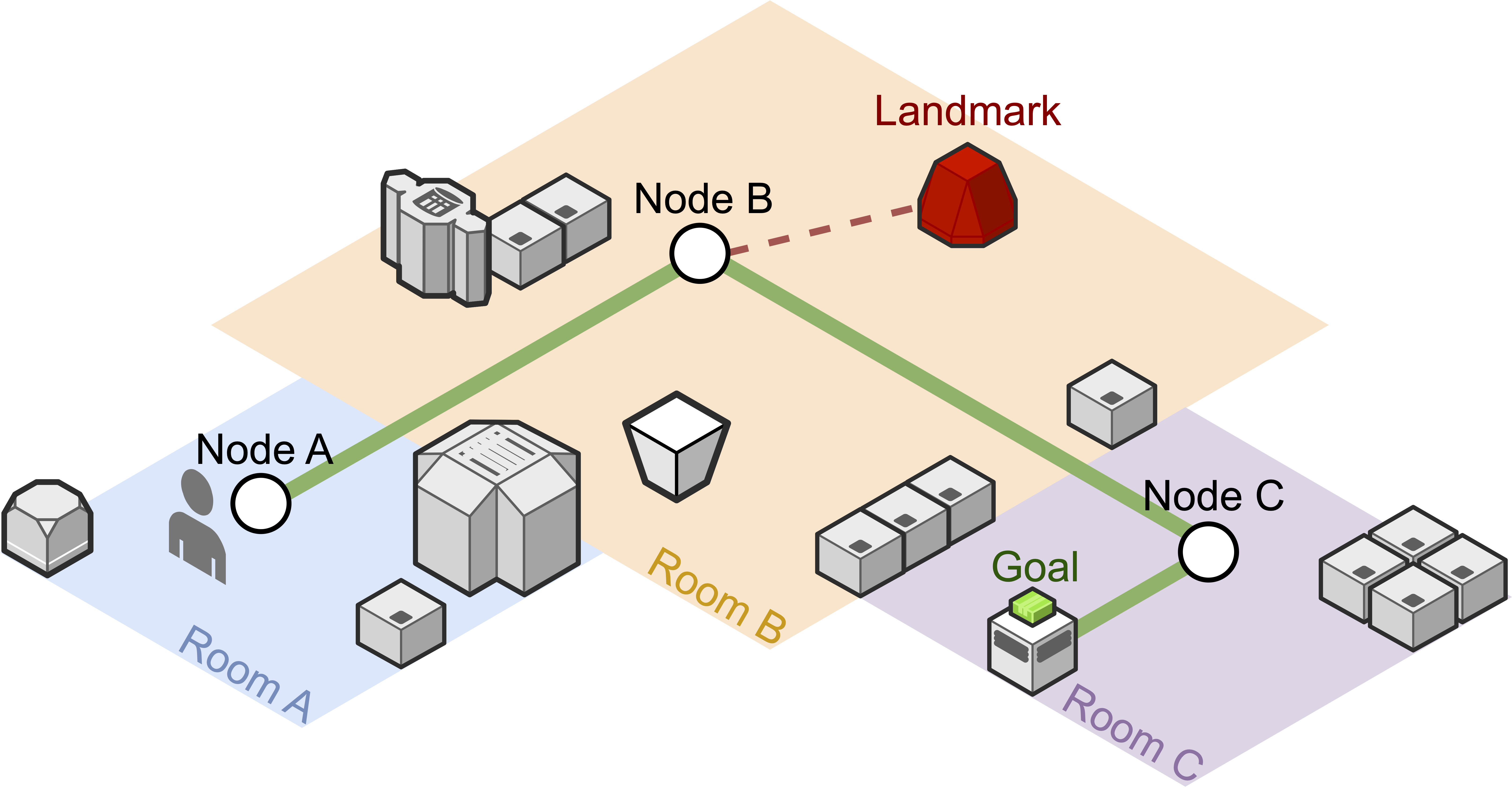
We propose a novel Landmark-Aware Visual Navigation (LAVN) dataset for map representation research. LAVN provides unique landmark information (in red) in specific scenes to aid model navigation and exploration performance and map representation learning. In this figure, a human expert in Room A (in blue) provides a video-based training trajectory (in green lines) for navigation given a goal image (green box). Rooms are depicted in different colors and represented with nodes. Our dataset facilitates topological map representation learning by injecting novel landmarks into a robot’s observation.
Dataset Characteristics and Statistics
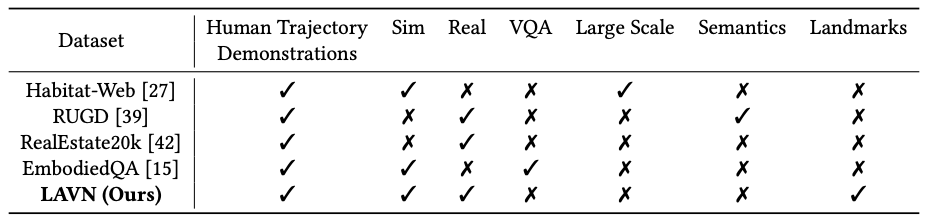
Summary of dataset characteristics for visual navigation. Different from existing datasets, LAVN provides video-based trajectories guided by humans in both simulated and real-world scenarios. We are the only dataset to provide labels for helpful navigational landmarks. These landmarks introduce little overhead to an agent’s learning scheme, as they do not necessitate the interpretation of the additional text modality as in VQA, or heavy semantic understanding of the environment. We are also the only dataset to provide human trajectory demonstrations in both real world and simulated environments. While we do not provide millions of data points, we allow for supervised model training, which removes the need for copious amounts of data.

Statistics of our dataset. We detail the number of trajectories, total number of frames per trajectory, landmarks, virtual environments, and real world environments included in the data.
Dataset Observation Examples

Samples of RGB images in our dataset captured from an ego-centric camera. Video frames start from left to right. Landmarks are visualized with red dots. Samples in the virtual dataset (1st and 2nd rows in blue) are visually realistic compared to the real-world observations (3rd and 4th rows in green), which makes landmark data acquisition scalable to serve real-world research purposes.

Samples of RGB images in the real world environments with landmarks annotated by red dots. Trajectories are recorded in comprehensive environments both indoors and outdoors.
