Feudal Networks for Visual Navigation
Click here to read the paper.
Abstract
Visual navigation follows the intuition that humans can navigate without detailed maps. A common approach is interactive exploration while building a topological graph with images at nodes that can be used for planning. Recent variations learn from passive videos and can navigate using complex social and semantic cues. However, a significant number of training videos are needed, large graphs are utilized, and scenes are not unseen since odometry is utilized. We introduce a new approach to visual navigation using feudal learning, which employs a hierarchical structure consisting of a worker agent, a mid-level manager, and a high-level manager. Key to the feudal learning paradigm, agents at each level see a different aspect of the task and operate at different spatial and temporal scales. Two unique modules are developed in this framework. For the high-level manager, we learn a memory proxy map in a self supervised manner to record prior observations in a learned latent space and avoid the use of graphs and odometry. For the mid-level manager, we develop a waypoint network that outputs intermediate subgoals imitating human waypoint selection during local navigation. This waypoint network is pre-trained using a new, small set of teleoperation videos that we make publicly available, with training environments different from testing environments. The resulting feudal navigation network achieves near SOTA performance, while providing a novel no-RL, no-graph, no-odometry, no-metric map approach to the image goal navigation task.
Overview
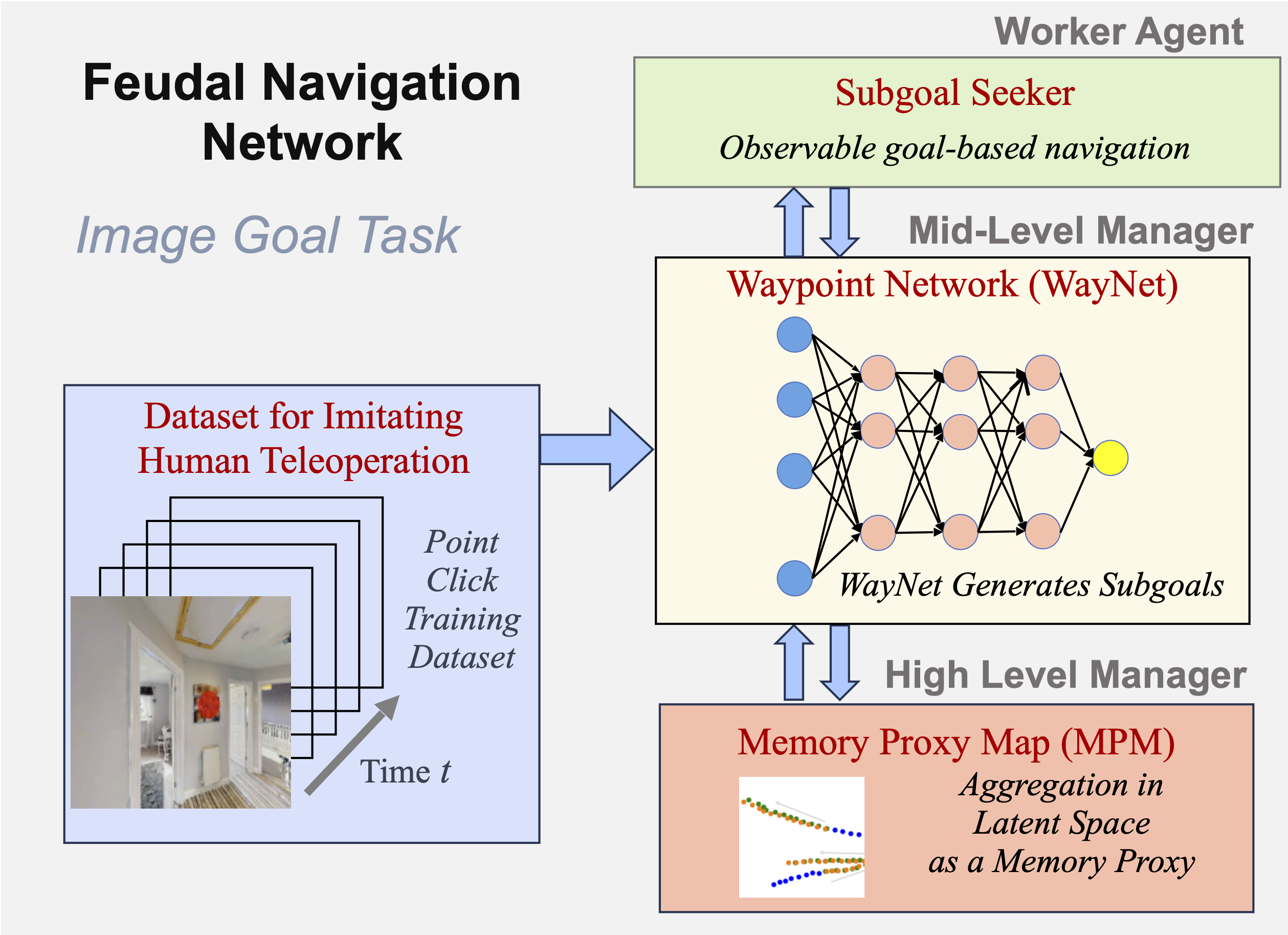
Feudal Navigation Network (FeudalNav), providing a no-odometry, no-graph, and no-metric map visual navigation agent for the image- goal task on previously unseen environments. The three main components are: (1) a high level manager that creates a memory proxy map (MPM) to use as an aggregate observation to make high-level navigation decisions, (2) a mid-level manager waypoint network (WayNet) that mimics human teleoperation by predicting visible points in the environment to guide worker agent exploration, and (3) a low level worker that finds the subgoal using robust point matching.
Human Navigation Dataset

For more information about this dataset, click here.
Samples of RGB images in our human navigation dataset captured from an ego-centric camera in both Gibson and Matterport environments. Video frames start from left to right. A human provides point-click guidance for robot visual navigation visualized with red dots.
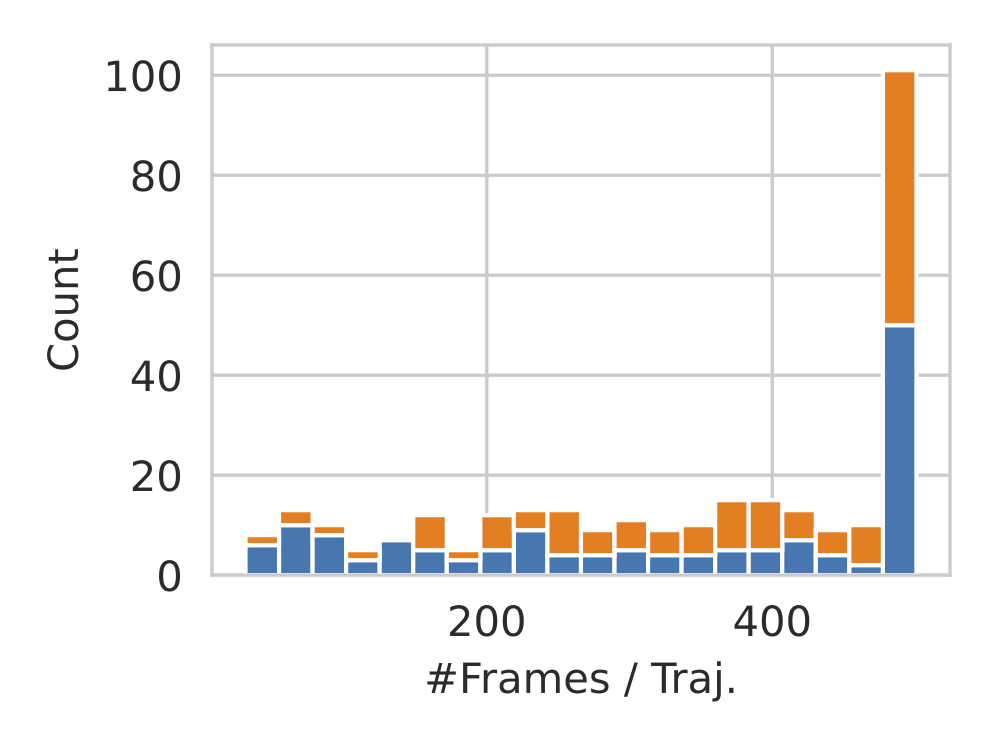
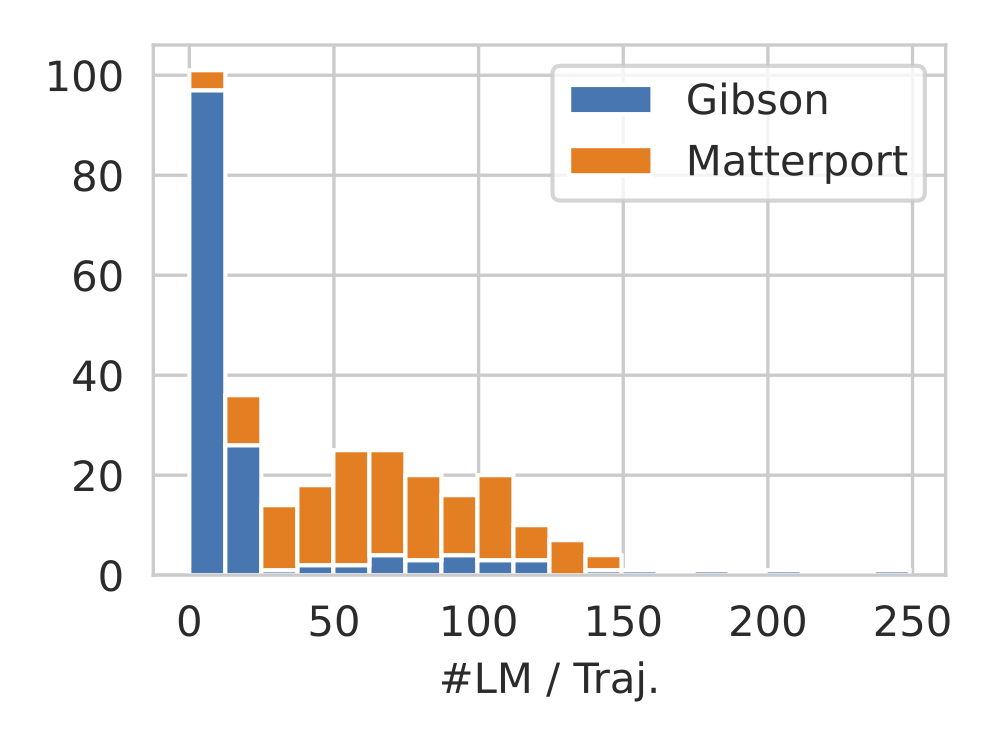
Stacked histograms depicting the number of frames (#Frames) and the number of landmarks(#LM) per trajectory. Left: The majority of trajectories consist of the maximum #Frames, which is 500. The number of human point-click waypoints is equal to the number of frames for each scene. Right:Most trajectories in the Gibson rooms consists of only a small number of annotated landmarks (e.g. > 25), while it increases in Matterport due to its larger and more complicated environments.
Networks
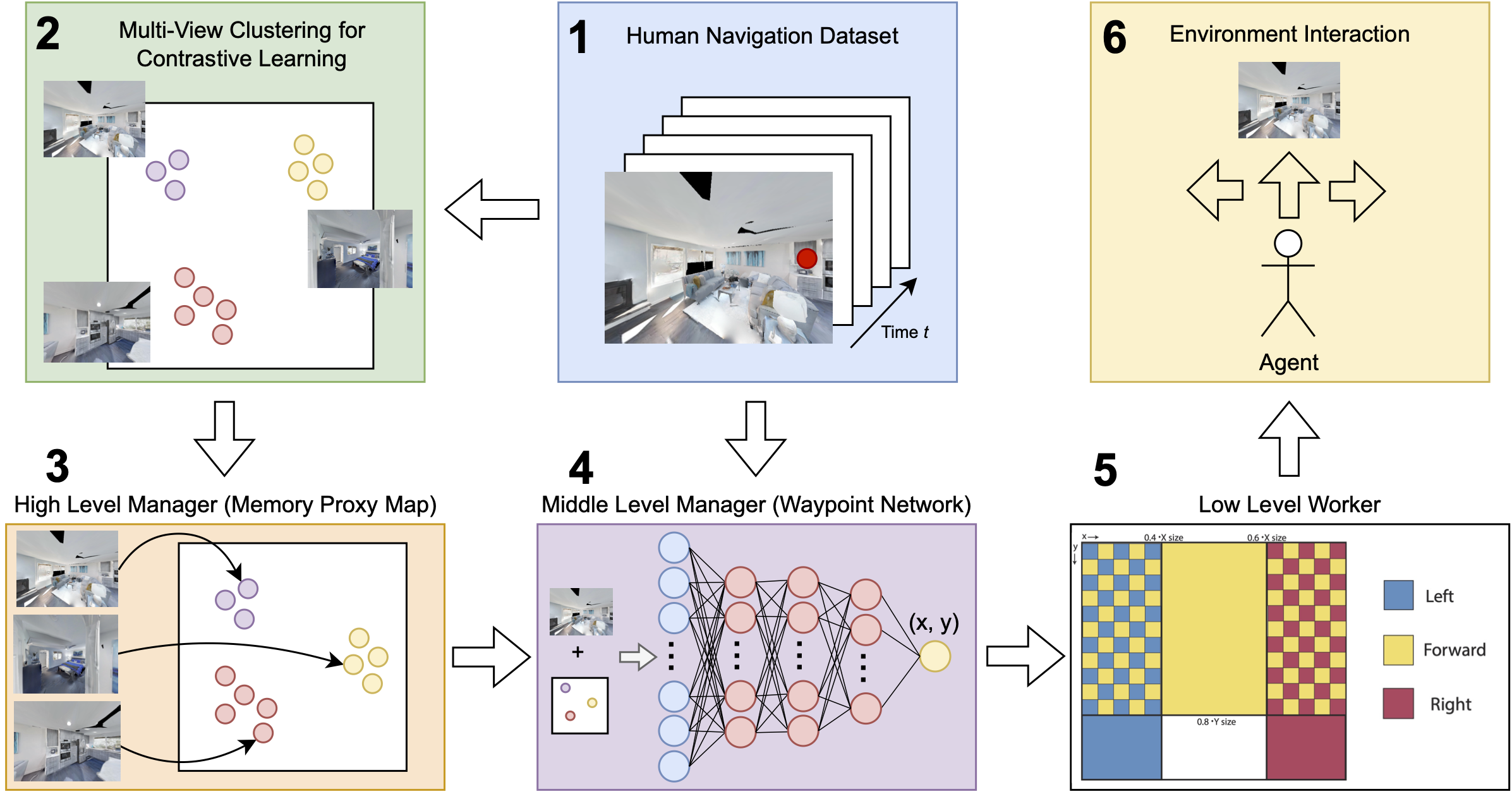
1: Point click data is collected while human teleoperators direct agent exploration of different environments. The resulting set of point-image pairs comprise the human navigation dataset. 2: From this dataset, we find clusters of observations based on feature similarity. 3: These clusters are used to provide positive pairs to train the navigation memory module that serves as the high level manager (HLM) for our navigation agent. During test time, this HLM creates a map of historical agent locations (memory proxy map) in the learned space. 4: These maps are created for the human navigation dataset and used to train the mid-level manager. During training, the memory proxy map and the current observations are used to predict human-like point click supervision to guide environment exploration. 5: Based on this point click guidance, the worker executes low level actions directly in the simulated environment. (See the figure below) 6: During test time, these low level actions guide agent movement and produce new observations as input for the upper levels of the hierarchy.
Low Level Worker Actions
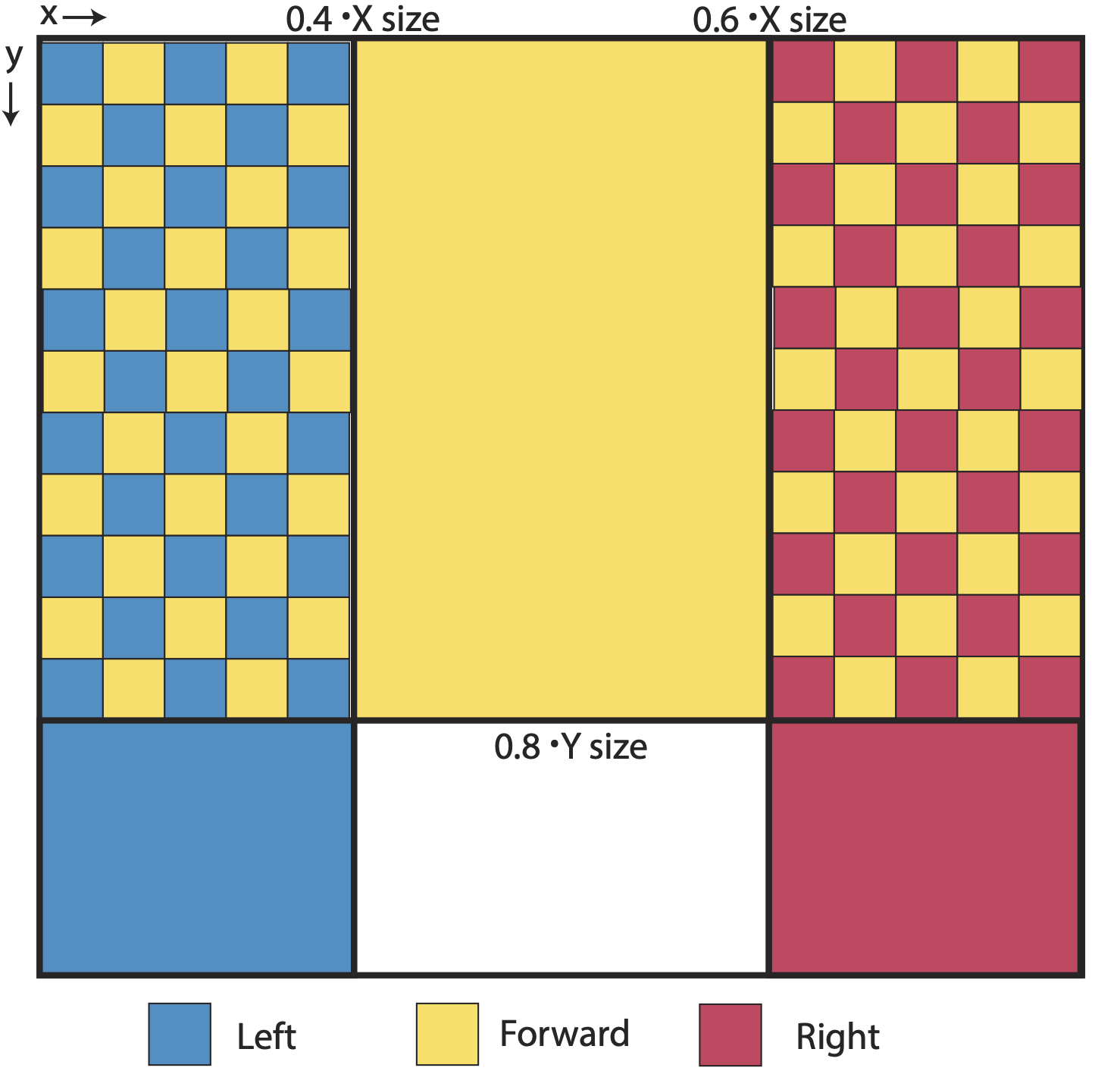
Map showing which mid-level manager point click locations map to which simulator actions for the low level worker. The bottom left grid (blue) and the bottom right grid (red) correspond to “turn left” and 11turn right” respectively. The center middle grid (yellow) corresponds to “move forward”. The top left grid (blue and yellow) and the top right grid (red and yellow) correspond to the joint action of turning (left for blue and right for red) and moving forward sequentially. The two vertical delineations are at 0.4 and 0.6 times the x dimension of the observation respectively. The horizontal line is drawn at 0.8 time the y dimension of the observation.
Mid-Level Manager Accurately Mimics Human Navigation

We show qualitative results for the waypoints predicted by WayNet (blue) juxtaposed with the ground truth human click points from the human navigation dataset (orange). Note that the majority of the samples show high overlap between the two. When they diverge, the WayNet waypoints still lead to navigably feasible areas in each observation. (Best viewed zoomed)
FeudalNav Outperforms Baselines and SOTA
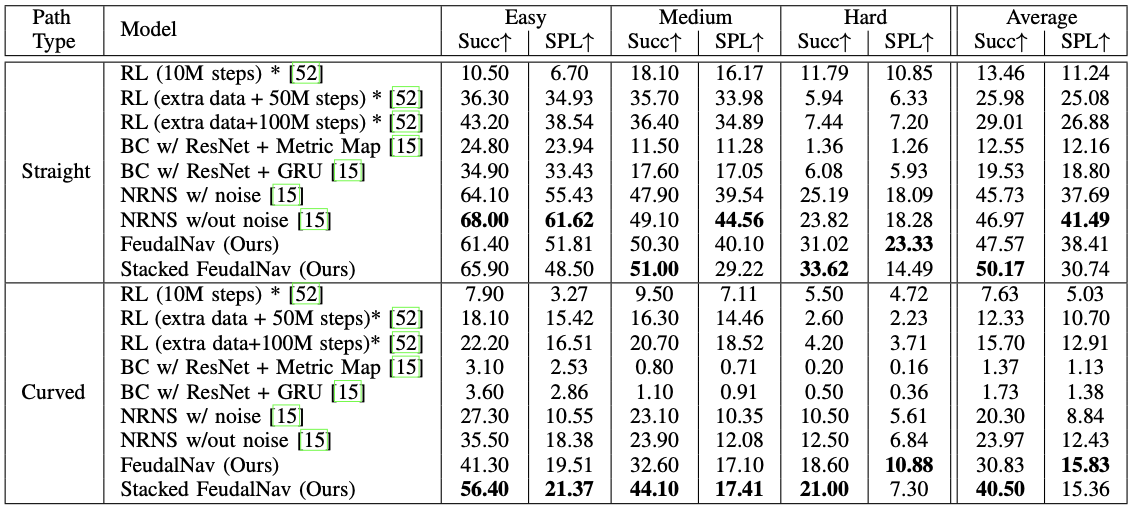
Quantitative comparison of our method (FeudalNav and Stacked FeudalNav) against baselines and SOTA on the image goal task following the evaluation protocol from NRNS in previously unseen environments. The top results are bolded for each category. We show a 69% and 27% increase in performance (success rate and SPL respectively) on curved trajectories on average over NRNS, and a 7% increase in performance on straight success rate. (* denotes the use of a simulator during training)
Different Network’s Effects on the Memory Proxy Map

We compare feature distances between all pairs of images in an example trajectory from the human navigation dataset for different self-supervised contrastive learning methods against the ground truth distances for each pair of images. Lower feature distances are darker/purple and higher feature distances are brighter/yellow. We show that SMoG learns a latent space that preserves ground truth distance trends the most, making it the most suitable for the memory proxy map.
Ablation Study
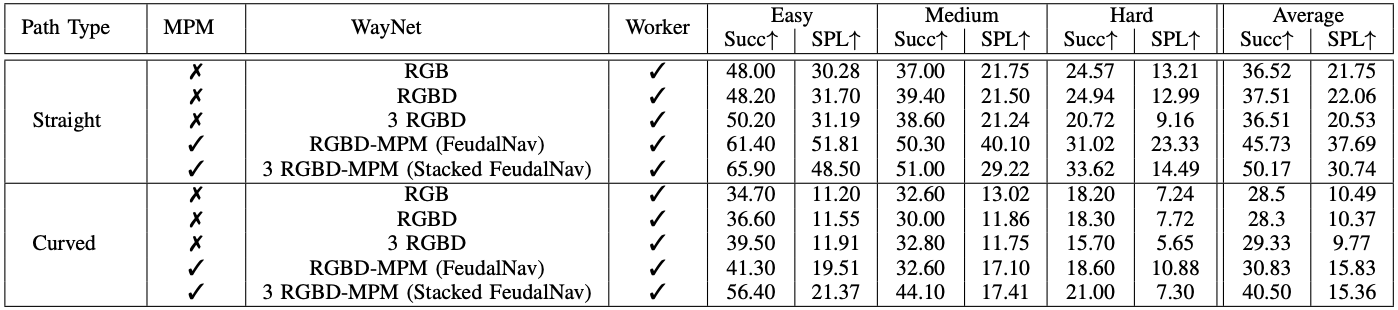
We conduct an ablation study showing the effect of each module in FeudalNav on overall image-goal task performance. Despite similar success rate and SPL, we find a qualitative improvement as we add depth and 3 historical frames to the input to WayNet. We see large performance improvements as we add the memory proxy map as input as it allows the network to have a notion of observation frequency and helps to localize the agent in the environment.
